
您的位置:主页 > 公告动态 > 投资资讯 > 投资资讯
70000亿虚晃一枪,硅谷的「刀」刺向英伟达-香港
“我们的英伟达芯片贮备,已经跟不上了。”一位AI大模子企业CEO坦言。
受出口管制进一步收紧的影响,A800、H800等中国*版芯片已经很难正常采购,取而代之的是合规版H20,后者性能大幅缩水,外界也将其称之为阉割版。即便云云,H20仍然有可能在今年10月份美国商务部出口管制条款更新当中,同样面临出口管制。
《金融时报》援引两位与英伟达关系亲热的匿名人士新闻称,多家中国公司向英伟达下单订购了共50亿美元的芯片。与此同时,一些国产芯片进入科技大厂的视野,但由于工艺、互联等缘故原由,性能仍有差距,供应也存在挑战。
在这种靠山下,多家大公司下场自研,先后在台积电流片,笼罩5nm、7nm等多个工艺节点,以保证自身AI芯片的供应平安。
出口管制像一把双刃剑,卡住了算力的脖子,也限制了英伟达的增进,尤其是在客户自研的靠山下,英伟达在大陆的营收最先泛起变数。2022财年,中国客户为英伟达孝顺了25%的市场营收,而到2024财年,这个比例已下降至个位数。
对英伟达来说,中国大陆的蛋糕缩水,硅谷也在变天。谷歌、苹果、Meta、亚马逊、特斯拉等大客户都在实验两条腿并行,一边用着英伟达的芯片,一边下场自研。
中、美大厂自研芯片的逻辑是什么,涌进红海的科技公司,靠自研芯片能顺遂上岸吗?
硬通货,握在手里才有平安感
01
大模子和天生式AI热潮狂卷的当下,算力芯片是科技公司手里的硬通货,芯潮IC曾在一文中跟踪过这种“抢算力”的疯狂与主要。
把牌握在自己手里,是大厂自研芯片的基本缘故原由。
在千芯科技董事长陈巍看来,大厂的底牌有三张:保供、降本和竞价,笼统来说是一种芯片自主权。
对许多中国大厂,稀奇是互联网和人工智能大厂来说,在先进芯片出口管制的靠山下,随时面临算力断供风险,下场自研是算力平安的保障。不外,各家开发的芯片主要是内部自用,规格也是针对自家产物定制设计,并非通用型产物。
对“烧钱”堆算力的巨头们来说,自研是降本的一条路径。“体量足够大、需求足够大,再思量自研,否则纷歧定能真的降本。”前台积电建厂专家吴梓豪说。
2021年,马斯克推出了由自研AI芯片D1打造的Dojo超级盘算机,用以训练特斯拉的自动驾驶系统。据摩根士丹利最新研报,这套系统比用英伟达的A100,足足省下了65亿美元。
随着AI需求兴起,云厂对GPU的依赖性远远跨越了CPU,对英伟达芯片的需求称疯狂,自研也是云厂抢英伟达订单的竞价筹码。
一位靠近亚马逊的人士告诉芯潮IC,英伟达的卡并未廉价,DSA大厂若是手握自研的专用芯片,不只可以充实降低在芯片和专利上的平均成本,面临英伟达也能有更好的议价权。
公然资料显示,亚马逊不仅设计自己的盘算服务器、存储服务器、路由器,还研发了自己的服务器芯片Graviton。

AWS推出通用Graviton4处置器
据The Information报道,亚马逊通过Graviton替换英伟达来连续降低价钱,客户租用Graviton服务器,直接节约了10%~40%的盘算成本。站在英伟达的角度,要留住亚马逊这种全球*的云厂客户,就得坐在牌桌上,协商出一个更好的价钱。
“这种让利,有时刻纷歧定完全反映到折扣上,有可能反映在设置上。”
上述知情人士透露,作为全球*的现货厂商,英伟达若是直接在单价上给予异常直观的折扣,对产物订价系统的负面影响会很大,晦气于产物价钱珍爱,但它们可以通过升级互连装备、升级SSD存储、增添更多Rack设置等方式,变相给大客户提供优惠。
另有一种更为常见的优惠手段——产能倾斜,提供首发权益。
拿到先发优势,亚马逊在短期内可以把整机价钱定得更高,从整机溢价和配套软件工具链的流通当中,把(折扣)钱“省”出来。
保供、降本和竞价之外,有些大厂自研芯片更多是想要保证自身怪异的竞争力。
风云学会副会长陈经提到,英伟达卖的芯片适用于通用盘算,功效很全但也对照贵,但有些客户只需要特定的功效来强化自身的某些优势,这种情形下就会思量自研。
“我只需要做大模子推理,不需要训练功效,这种情形就可以设计一个功效简朴,然则速率更快,价钱廉价的专用芯片,”陈经说。“像谷歌、微软这些大公司,都有自己的软硬件系统规范,若何去控制噪音,能耗要到什么级别,英伟达纷歧定能知足尺度,自己设计会更利便。”
硅谷巨头当中,谷歌异常在意自身架构、成本和芯片手艺的差异化,从2016年起就自研AI张量处置单元(TPU),以便于在大中型训练与推理中,获得更好的成本效益和性能,以保证自己的云盘算产物有更好的怪异征和识别度。
谷歌推出第六代TPU“Trillium”
凭证谷歌披露的第4代TPU相关数据,与一致规模的系统相比,TPU v4的效率比英伟达A100强1.7倍,节能效率强1.9倍。
除以上几点外,从生态角度来看,另有一个更深层的缘故原由——打破CUDA垄断。作为英伟达研发的编程语言,CUDA是把GPU价钱“炒上天”,而客户又不得不接受的主要缘故原由。
若是云厂不做自研,即便可以拿到很好的订单价钱,但数据中央超95%的处置器依然要用英伟达GPU,整个云上AI需求仍要依赖CUDA生态。说到底,命门照样捏在英伟达手上。
随着云厂在数据中央配备自研芯片,同时开发许多底层中央件和二进制翻译功效,辅助客户迁徙至自家生态,对CUDA程序的等价兼容水平会更高,*的依赖水平会逐渐减轻。
“这是所有的云厂都在做的事,即便处置器在整个数据中央所占比可能不到4%,但依然要坚持做这个事情。”该知情人士说。
有人、有钱,那就下场吧
02
“有人、有钱、有事,同时它另有未来的量,那就可以下场了。”
遐想控股副总裁于浩以为,大厂做芯片自研的逻辑是对照顺,它的客户就在那儿,这是个明确的优势。
“‘人’得是有芯片全生命周期实战履历的‘牛人’,‘钱’得是依托算力营业连续孝顺收入的‘活钱’,这样一来,大厂依托AI营业闭环,清点未来可预期的市场涨幅,量化算力需求,完成人和钱的战略统筹,自研芯片水到渠成。”于浩告诉芯潮IC。
不外,坐上自研这个牌桌,入场费至少20亿美元起。今年头,OpenAI CEO山姆·奥特曼甚至传出了筹资7万亿美元造芯片的疯狂设计,只管厥后当事人对这一听说给予了否认。
据知情人士透露,“每家迭代*代产物,若是按7纳米中央节点去算,加量产至少小20亿美金。”
此外,自研芯片更多是自用,可以不思量建设生态的难度。燃次元援引天鹰资源合资人的看法示意:“专用芯片在架构设计上一样平常不用稀奇庞大,应用特征也很明确,开发相对快速,因而对于许多互联网公司来说,他们开发专用芯片就在于有明确场景,不需要花太多财力和时间去搞定软件生态,工艺IP也成熟。”
理论行得通,详细自研这件事若何才气玩儿得转?
根据业内认知,芯片自研这件事可以拆分成前、后端两部门。前端即逻辑设计,是芯片最基本的一些功效,后端是物理设计,是把所有的功效落实到电路而且流片出来的实体。
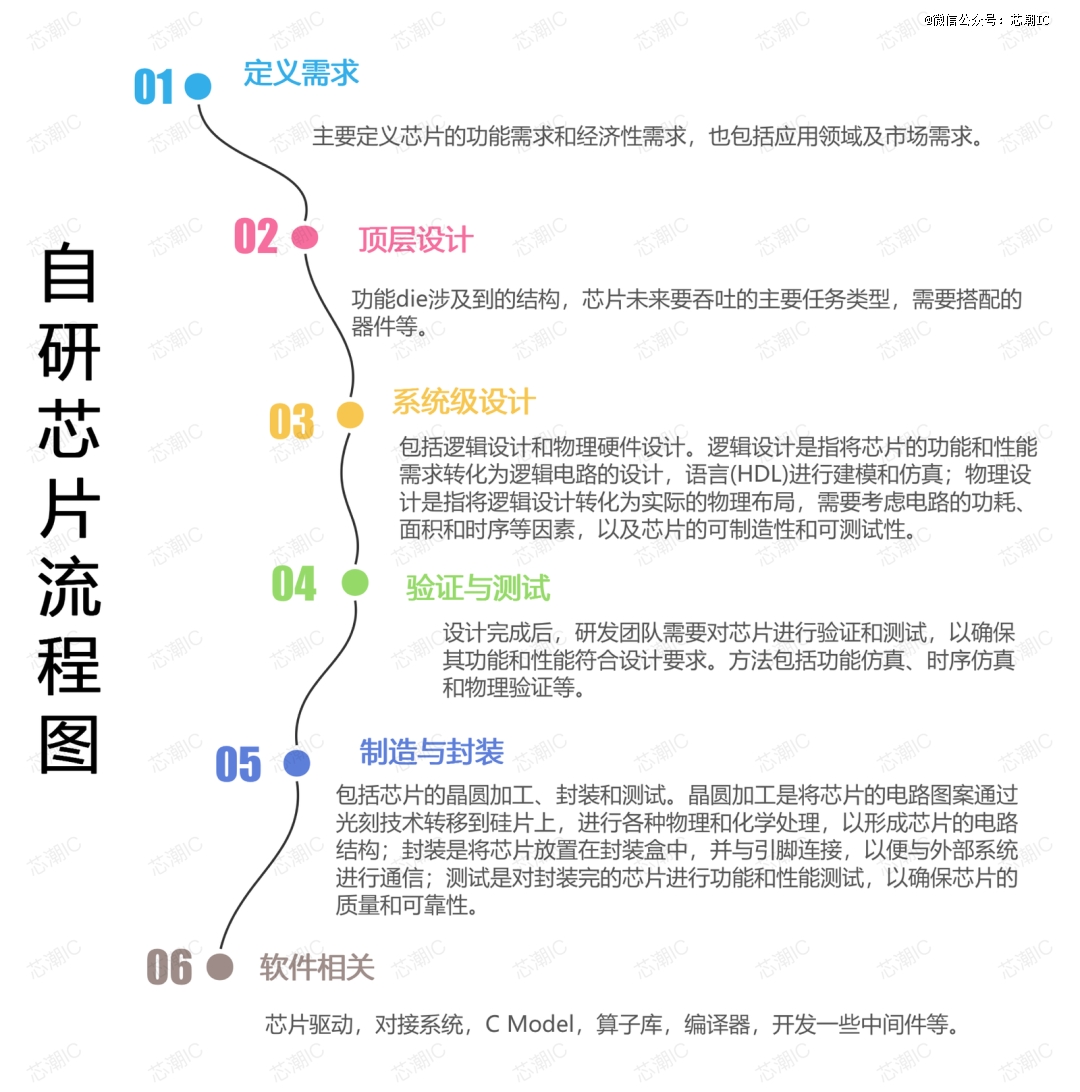
自研芯片流程示意图
小团队一样平常来讲能够自力完成的设计只有逻辑芯片的前后端和软件工具链自己,但即便云云,许多设计也仅有5%的自研专用电路。
前述知情人士示意,“市场上人人都是自己做1/5,其余的4/5找别人做,这是相当成熟的生态。至于若何获得这些电路IP,有一些是不良渠道,有一些则是合规的渠道,好比ARM这样的IP设计厂商授权。”
对于许多团队来说,实在具备部门电路的自主设计能力,但由于需要逾越有异常严密的知识产权珍爱的IP,就算做出来也很可能违反了盘算机系统结构没有设施使用,甚至侵略了别人的IP,这也是海内厂商自研芯片时碰的*道坎儿。
大厂的新竞赛:年薪百万抢人,一年猛推50款产品
另有一部门器械简直是自研团队设计不了的,好比NOC(Network on Chip,片上网络)一些异常深邃的结构。
设计只是自研芯片的一个环节,它还包罗流片、量产等等,中央可能还会遇到林林总总的问题,包罗流片失败,量产产能等,但这些都不是自研的终点,它还需要解决一系列的配套问题,包罗若何将产业链整合落到实处。
在外界看来,一颗专用的逻辑芯片也许500多mm²,通用的GPU可以做到800mm²,包罗数百亿甚至上千亿晶体管,其中一部门功效用于向量盘算,可以以为是一个向量处置器的所有,但要落地到应用场景当中,它还需要存储、能耗控制、供电、整机工况方面的设计与实现,也需要互联组网酿成更大的集群。
此外,产物的最终目的都是打出差异化,这需要在外设接口和整机上做,也就会泛起差其余SKU,而行业通常也是从整机的角度去对比存储、能耗、坪效。
也就是说,自研芯片除了产业链整合、IP的问题,也得思量做产物SKU,不是设计出一颗逻辑芯片就可以了。
一位不愿透露姓名的资深人士告诉芯潮IC,“许多海内公司不具备产物设计能力,做出芯片之后,要到各地去测试,它的工程师、商务BD每一天都驻扎在浪潮、曙光等大厂的数据中央,期待对方新的服务器主板上能够去留一个插口给自己,测试乐成就批量买一批,不外现在乐成简直实异常少。”
量产,是设计、流片以及产物化之外的另一个挑战。小团队必须思量,事实能不能够预定到产能?
“产量永远对Fab厂是一个异常要害的数字。”前台积电建厂专家吴梓豪示意,厂商要掌握自己在哪个环节进入,答应多大的产量,这是感动Fab最要害的点。
一线厂商基本都是在DTCO(设计手艺协同优化)阶段,就已经预定到了Fab厂的最新产能,现在全球最*的设计团队,好比ARM每年有大批的人驻扎在台积电,包罗许多EDA厂商也是。
DTC决议了下一代处置器在详细节点上的性能指标,好比通过在3nm节点,通过合理的结构设计,能节约若干钱、可以提升若干性能。
“英伟达、苹果永远愿意试水*进的制程,只要台积电出一个*进的制程,哪怕良率未知,性能的增益未知,即经济模子还算不出来的时刻,他们就已经在预定产能了,与Fab厂举行DTCO协同设计,这是一线厂商拿到产能的基本缘故原由。”吴梓豪说。
若是没有从一最先做协同设计,Fab厂与Fabless团队,甲乙双方就得转换角色,由于人人都不太敢用,Fab厂只能一点一点去推销自己的新制程,先从风险*的芯片最先。
好比矿机芯片,结构异常简朴,尺寸又稀奇小,就很适合最初的试水,昔时三星3nm芯片的*客户就是一家来自中国的矿机装备厂。
吴梓豪说,“Fab厂在这种小客户订单上试水乐成后,才气再试着量产PC的CPU,手机芯片,最后是AI芯片,一步一步来。”
现在,海内大厂自研芯片至少已投入了数十亿美金。若是初创公司想入局,要么自己有足够的多的早期客户,或有应用平台去支持芯片的适配与试错,要么有足够的资源或融资能力很强,这两个条件必须知足其一。
陈巍告诉芯潮IC,若是是一家没有低成本人力贮备的商业化公司,不依赖学校或研究所,那在量产之前需要不低于5~10亿人民币的融资;但若是有研究所或其他支持的话,人力成本能削减许多,金额门槛可稍微低一些。
“若是没有那么多钱,但这家创企的成本控制能力异常强,能充实行使好上下游协作来降低成本也可以,一切都是为了保证产物研发的连续举行。”
Fab选择优先级上,据知情人士透露,最初创企们会选择去订购台积电的产能,其次是格芯,但格芯没有先进工艺,也没有封装,再转而找中芯国际,但中芯国际能预订的产能都排到后年了。
对于这一情形,投资机构持更长线的视角。
于浩示意,单就海内自研高端芯片来说,短期内面临流片瓶颈是一定的,耐久就看以中芯国际为代表的先进工艺线打磨和产能扩充的进化速率,主要靠内循环。不外,有高端芯片设计能力的厂商,不妨思量出海,用外循环动员内循环,走出去反而天南地北。
做英伟达的“掘墓人”不容易
03
老客户自主门户,受伤的总是英伟达。
这一场全球局限的自研大潮,一个比一个“炸”。除了谷歌TPU、亚马逊Graviton这些已臻成熟的自研功效。克日,整个科技圈都被“全球*Transformer专用AI芯片Sohu”刷屏。

美国芯片创业公司 Etched 推出Transformer专用AI芯片Sohu
这款芯片直接将Transformer架构嵌入芯片内部,在推理性能上远超GPU和其他通用人工智能芯片,号称比今年3月才面世的*芯片B200性能凌驾10倍。据传,一台配备8块Sohu芯片的服务器,性能足以媲美160块H100 GPU的集群,每秒能处置高达50万的Llama 7B tokens。
“当红炸子鸡”横空出世,Fab厂及互助商笑开了花。
据悉,该公司已就Sohu芯片的生产与台积电4nm工艺睁开直接互助,而且已从*供应商处获得足够的 HBM 和服务器供应,一些早期客户已经向该公司预订了数万万美元的硬件。网友给Etched起了个诨名——“英伟达的掘墓人”。
但英伟达真会因狼烟四起而“自研”神话破灭吗?实在否则。
在半导体行业,有一个著名的“牧本周期”——芯片类型有纪律地在通用化和定制化之间不停交替演化——在某一个特准时期内,通用结构卖得*,为宽大用户所迎接,但到达一定阶段后,通用结构在应对特定需求时落伍,专用结构会大行其道。
而英伟达正义无反顾地代表着通用结构时代,这个时代恰好还处在巅峰。
凭证富国银行的统计,英伟达现在在全球数据中央AI加速市场拥有98%的份额,处于*的统治职位。这也就是说,全球98%的人群正在使用英伟达的CUDA C去“榨干”所有GPU的性能,只有剩下那2%-3%的人还在稀奇坚持用一个不怎么样的“锤子”,去锤统一个“钉子”。
“现在亚马逊也好,英特尔也好,自己做的处置器首先经济上不能知足一个云厂商利益的*化,以是他们一定还会大量使用英伟达芯片,直到有一天英伟达彻底失去优势,才会走到牧本周期专用化那条路上。”前述知情人士示意。
不外,躺平不相符英伟达的人设,黄仁勋是一个深知“生于忧患死于安乐”的人,一年前在台大的演讲,他就谈到:“岂论是为了食物而奔跑,或不被他人看成食物而奔跑,你往往无法知道自己正处在哪一种情形,但无论若何,都要保持奔跑。”
这次,面临整个硅谷自研的挑战,英伟达也在出牌。
前述资深人士告诉芯潮IC,“英伟达做的早就不是一个通用GPU了,在它的GPU单元中可以看到大量的Tensor Core来解决矩阵盘算,除此之外还能看到Transformer引擎、希罕化引擎等,无论在硬件结构,照样在硬件算子的更新上,英伟达每年都在把自己推向DSA化的设计趋势。”
DSA(Domain Specific Architecture)即特定领域架构,是一种针对特定领域定制的可编程处置器架构,能够优化特定应用程序的性能和性价比。现在,谷歌、特斯拉、OpenAI和Cerebras等都针对特定应用推出了自己的DSA芯片。
据知情人士透露,所有做DSA的厂商都市发现,英伟达纵然不修改硬件,通用GPU只更新一个算子,DSA厂商的优势就完全没有了。似乎与英伟达一比,自己不只逻辑芯片面积做得不够大,器件容量和速率做得也不够大,算力也比不上英伟达,软件适配性做得也不够好,这也是所有DSA厂商都面临的问题——牧本周期原本要走向DSA特定领域架构,走向定制化的,现在又回到了通用处置器的时代。
除了和DSA厂商“照镜子”,英伟达也向自研伸出了橄榄枝——2024年年头,专门确立了一个新的营业部门,由半导体资深人士Dina McKinney向导,专为云盘算、5G 电信、游戏、汽车等领域客户构建定制芯片。
路透社援引知情人士说法称,英伟达高管已与亚马逊、Meta、微软、谷歌和 OpenAI的代表们会晤,讨论为它们定制芯片的事宜,除了数据中央芯片外,该公司还在争取电信、汽车和视频游戏客户。
此前,有新闻称任天堂在今年推出的新版任天堂Switch游戏机,很可能就会搭载英伟达的定制芯片,而英伟达在掌机市场也有很深的沉淀,而且推出过Tegra系列移动芯片,只管这个芯片系列最后并没有在移动装备市场占有一席之地。
在性价比主导的市场里,要做英伟达的掘墓人还真没那么容易。之前的掘墓人大多走向了失败——最终可能会被收购,像英特尔、Google收购了许多创企,但此外的大多数企业甚至等不到收购,直接夭折了。
也许对于初创企业来说,换一个角度更容易乐成。
“好比不要执迷于AI处置器自己,与其花许多的时间去兑现一个DSA的理想,不如思量一下系统级方案,好比可以做周边外设来为 AI的处置器提供服务,做专业存储、专业传感器也可以到达同样的目的。”前述知情人士说。
2019年,英伟达宣布以69亿美金的价钱收购Mellanox,这个估值异常之高,英伟达险些透支掉自己的整个现金流。
这家公司既不研发端口,也不研发光伏模块,更不研发交流机自己,它只做了一款产物——交流机底层和通讯底层的那一部门高速互联的PHY“InfiniBand”。对于那时亟需突破服务器互连限制的英伟达而言,这是一个异常焦点的外设的需求。那时无论NVLink做得多好,始终被锁死在单机周围。但InfiniBand可以让交流机突破服务器间的互联瓶颈,把所有的GPU互联成一个大集群。
放眼当下,海内正火热攒局,芯片自研的子弹还得再飞一会儿。陈巍以为,攒局不是一件坏事,但要攒一个高端局,以免错失产业生长的要害窗口期。
未尽研究首创人周健工进一步睁开这一看法,他以为,往后的应用对于AI芯片的专业、定制、小型化需求,会超出对于前沿基础大模子的需求。以更低的成本训练出开源的、较小型的模子,或者对大模子举行微协调蒸馏等,以及推理,都为自研芯片带来了广漠的空间。而且在新手艺的快速更改和未成熟期,围绕上述应用会带来大量的自研时机。
“不要去做终结英伟达的事,而是去做英伟达之外更多的事。”